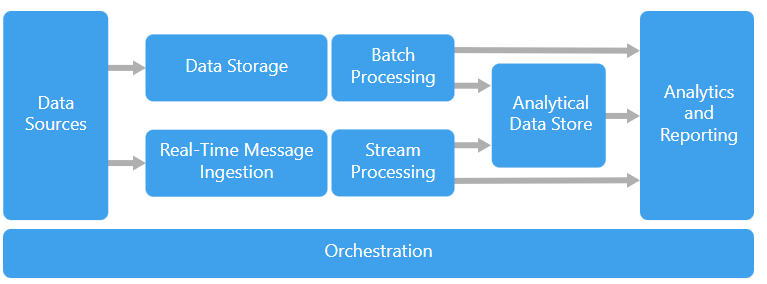
1. 정의 데이터 스트림을 실시간으로 관리하기 위한 비동기 메시징 큐 기능을 제공하는 시스템 pub/sub 메시지 큐: 펍/섭 모델 스트리밍 데이터를 처리 클러스터를 Scale out해야 할 경우 수십 대의 Broker(:Server node) 확장 가능 2. 구성도 및 구성요소 가. 구성도 나. 구성요소 메시지 구성요소 - topic(레코드 저장단위), partition(round robin, 기반) 파이프라인 - Publisher, Broker, Consumer topic, producer