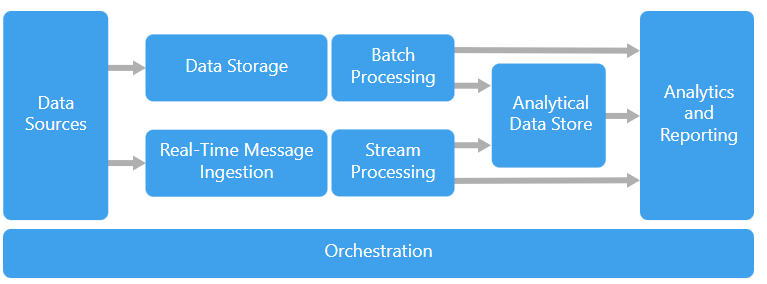
1. 정의 대용량 데이터 분산저장, 병렬처리 프레임워크 3.0 2. 주요 가. 운영 효율성 측면에서의 하둡 v3.0 특징 (이얀맵) Erasure Coding 도입 Fault Tolerance를 위한 Replication factor 3 이용 -> HDFS 3배 오버해드 발생(2.0기준) -> 1.4배로 축소 Read Solomon 알고리즘 FEC(오류 시에 정정할 수 있는 기술/전진 오류 수정/Forward Error Correction)) 기능을 넣어, 원본 데이터를 복원할 수 있는 기술 YARN Timeline Service v.2 도입 기존 타임라인 서비스보다 많은 정보를 확인 가능 데이터 쓰기와 읽기 분리, HBase 활용 : 분산처리 가능 확장성과 신뢰성을 확보 flows와 aggregatio..